Pillar 3: Cost Optimization
Pillar 3: Cost Optimization
(Prevent runaway autonomy, control token economics, and choose the right compute for the job)
Cost optimization in agentic systems is not a finance exercise—it is an architectural requirement. Agents are loops. Loops compound. If an agent is allowed to iterate freely, call tools freely, and expand context freely, cost becomes non-linear and unpredictable.
This pillar therefore starts from a hard constraint:
Autonomy without budgets is cost volatility by design.
A well-architected agentic system treats spend as a controlled resource in the same way we treat CPU, memory, or concurrency. The goal is not simply “reduce cost.” The goal is to ensure the system is economically scalable while maintaining reliability and safety.
7.1 What Actually Drives Cost in Agentic Systems
Agentic cost is typically driven by four interacting factors:
-
Model selection: Different models have different cost/latency/quality characteristics. Routing everything to the most capable model is rarely economical at scale.
-
Token volume (input and output)
Tokens are not only the user prompt; they include:
-
system instructions,
-
memory,
-
retrieved documents,
-
tool definitions,
-
tool outputs,
-
intermediate reasoning context.
-
Tool calls (actuation cost): Many tools have direct cost: API usage, search calls, compute time, database queries, build pipelines, etc.
-
Iteration count (loop depth): The number of turns in an agent loop (Trigger → Decide → Act → Verify) compounds the above costs.
This matters because these factors are coupled: large tool catalogs increase context, which increases token usage, which increases cost and latency, which can trigger retries and timeouts, which increases loop depth.
7.2 Cost as a First-Class Constraint: Budgets for Autonomy
The single most practical cost control in agentic systems is the introduction of explicit budgets. This includes limits on; some or all of the following:
-
maximum steps per task,
-
maximum tool calls per task,
-
maximum wall-clock time per task,
-
maximum token budget per task,
-
maximum spend per task (where measurable),
-
Communication thresholds when budgets are exceeded.
This is not merely a pragmatic “good idea.” It is supported by empirical research.
The paper Budget-Aware Tool-Use Enables Effective Agent Scaling shows that simply granting agents larger tool-call budgets does not reliably improve performance. Agents often hit performance ceilings because they lack budget awareness—they spend resources inefficiently and fail to allocate effort intelligently. The authors introduce budget-aware methods that improve cost-performance tradeoffs and push the Pareto frontier, explicitly modeling tool calls and token usage as a unified cost metric. (arxiv.org)
The practical architectural interpretation:
Budgets do not only cap cost. They shape behavior.
They force planning discipline, early stopping, and verification-based termination.
This links directly to the horizontal “Autonomy & Outcome Governance” layer: budgets determine how far autonomy can go before escalation.
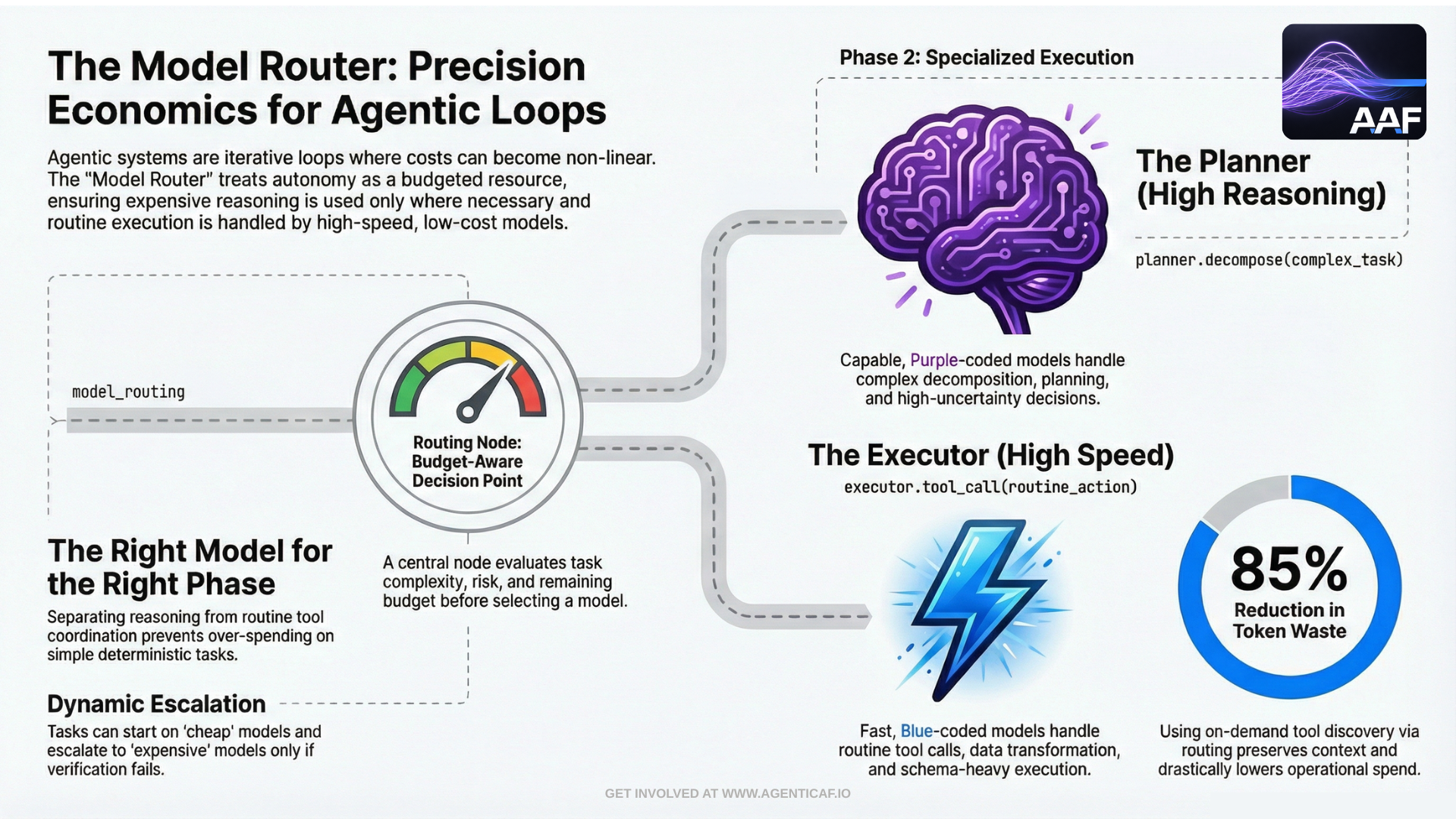
7.3 Right Model, Right Phase: Planning vs Execution
A consistent pattern in effective agent architectures is phase separation:
-
use more capable models for planning, decomposition, and risk-aware reasoning, and
-
use smaller/faster models for execution, transformation, classification, and routine tool coordination.
This is not about “big model vs small model” as ideology. It is simply matching compute to task. OpenAI’s production guidance explicitly frames cost optimization as a set of levers that include model choice, prompt design, and system architecture decisions rather than only token trimming. (platform.openai.com)
In practice, model routing often takes one of three forms:
- Static routing by task class
E.g., “planning” always uses a stronger model; “formatting” uses a smaller one.
- Dynamic routing by risk and uncertainty
E.g., if the agent is about to invoke a write tool or cannot confidently verify an outcome, escalate to a stronger model or to human approval.
- Cascaded routing
Start cheap, then escalate only if verification fails. This is cost-optimized and reliability-oriented: you only spend more when you have evidence that the cheaper route was insufficient.
7.4 Token Economics: Context Discipline and Output Control
Token spend is not an implementation detail; it is the operational cost footprint of the agent’s cognition. Two design principles matter most:
7.4.1 Control output length aggressively
In many workloads, output verbosity is a hidden cost multiplier. You want outputs that are:
-
structured,
-
bounded,
-
directly usable.
OpenAI provides direct implementation guidance on controlling response length through explicit limits and stop sequences. This is a core cost lever because it prevents “runaway verbosity” and wasted output tokens. (help.openai.com)
7.4.2 Reduce context bloat through tool discovery and retrieval patterns
A large portion of token waste in agent systems comes from stuffing too much into context:
-
long histories,
-
irrelevant memory,
-
full tool catalogs,
-
repeated system prompts.
Anthropic’s tool search approach quantifies the token impact of tool catalogs. In their Advanced Tool Use write-up, they show that discovering tools on-demand rather than loading all tool definitions upfront can preserve context window capacity and reduce overhead. They report an 85% reduction in token usage while maintaining tool access. (anthropic.com)
This is directly aligned with the context optimization foundation: the agent cannot be economically scalable if every task begins by paying a large fixed “context tax.”
7.5 Prompt Caching and Reuse: Design for Repetition
Agent systems are structurally repetitive:
-
the same system instructions,
-
the same guardrails,
-
the same tool definitions,
-
repeated plans and checklists.
Caching is therefore one of the highest-leverage cost controls available when building with LLM APIs.
OpenAI’s prompt caching documentation states that prompt caching can reduce input token costs substantially by reusing recently seen prompt prefixes and can also reduce latency. It works automatically when repeated prompt segments are present. (platform.openai.com)
OpenAI also provides implementation guidance and examples on how to structure prompts to maximize caching benefits. (developers.openai.com)
Architecturally, this implies a clean design rule:
Put stable instructions and static context in a consistent prefix.
Append variable task-specific context at the end.
This benefits both caching and governance (stable policies remain stable).
7.6 Early Stopping and Verification-Based Termination
In agent systems, cost is often dominated by “one more loop.” A reliable, cost-optimized agent must have a disciplined stopping rule.
The budget-aware agent scaling research makes this explicit by focusing on scenarios where agents are allowed to stop early without exhausting all tool calls—reflecting realistic deployments where a confident verified answer is preferable to prolonged exploration. (arxiv.org)
This supports a foundational pattern:
-
observe,
-
decide,
-
act,
-
verify and stop as soon as verification passes.
This is also an epistemic gate: the system stops not when it “feels done,” but when it can demonstrate completion against a definition of done.
7.7 Scheduling, Batching, and Workload Shaping
Many agent tasks are not time-sensitive. Research, indexing, evaluation, summarization, memory compaction, and background reconciliation can often be moved off the critical path.
Cost optimization therefore includes classic distributed systems workload shaping:
-
schedule batch work off-peak,
-
run background tasks asynchronously,
-
coalesce repeated triggers,
-
Avoid per-event “immediate reasoning” when a queue can smooth the workload.
This is not only cost-driven. It improves reliability and performance by reducing peak load, which reduces tool failures and rate limiting, which reduces retries and loop depth.
7.8 Cost Optimization as a Governance Concern
Cost optimization is not merely “reduce spend.” In agentic systems, cost is a form of governance:
-
budgets define how far autonomy can go,
-
routing policies define acceptable trade-offs,
-
output constraints define how the agent communicates,
-
context policies define what the agent is allowed to “see.”
This is why cost optimization sits tightly adjacent to:
-
Autonomy & Outcome Governance (budgets, escalation),
-
Context Optimization (token discipline),
-
Reliability (verification-based stopping),
-
Security (prevent cost-based DoS and runaway loops).
In short: cost is a control surface. Architect it accordingly.
7.11 Design Recommendations & Trade-offs
Key recommendations
- Architect context management with explicit budgeting, just-in-time retrieval, summarization, and provenance tracking.
- Enforce explicit, non-bypassable budgets on steps, tool calls, tokens, time, and spend as a primary mechanism for governing autonomy.
- Balance accuracy, latency, and cost for the specific workload by selecting the right model, rather than defaulting to the largest.
- Use more capable models for planning and high-risk reasoning, while using smaller, cheaper models for routine execution and transformation.
- Apply rate limiting and quotas at the agent's communication boundary to mitigate resource-driven attacks.
Cross-pillar trade-offs
- Cost x Context: Providing excessive context to an agent increases token volume, which directly increases operational costs. Architect context management with explicit budgeting, just-in-time retrieval, summarization, and provenance tracking. (source: 4.2.A)
- Cost x Autonomy: Granting an agent high levels of autonomy without enforced budgets for its actions (steps, tool calls, tokens) leads to unpredictable and potentially runaway operational costs. Enforce explicit, non-bypassable budgets on steps, tool calls, tokens, time, and spend as a primary mechanism for governing autonomy. (source: intro)
- Cost x Performance: Improving performance by using more powerful models or longer context windows directly increases token consumption and overall operational cost. Balance accuracy, latency, and cost for the specific workload by selecting the right model, rather than defaulting to the largest. (source: intro)
- Cost x Reliability: Using the most capable (and expensive) model for all tasks to maximize reliability is often not economically scalable. Use more capable models for planning and high-risk reasoning, while using smaller, cheaper models for routine execution and transformation. (source: 7.1)
- Cost x Security: A lack of security controls, such as rate limiting, makes an agent vulnerable to denial-of-service or runaway loops that cause excessive, uncontrolled costs. Apply rate limiting and quotas at the agent's communication boundary to mitigate resource-driven attacks. (source: 5.1)
By autonomy level
- Assistive:
- Cost x Context: Large context volumes increase token costs per interaction even when the human only needs a summary.
- Cost x Autonomy: Cost remains human-controlled, but agents should surface cost estimates alongside proposed plans.
- Cost x Performance: Fast, expensive model defaults shift the cost/speed trade-off to the human for every query.
- Cost x Reliability: Default to cheaper models for simple tasks; expensive models add cost without proportionate reliability gain.
- Cost x Security: Repeated queries can drive up inference costs even without action execution — apply rate limiting.
- Delegated:
- Cost x Context: Plans requiring large context payloads force the approver to accept high-cost actions without alternatives.
- Cost x Autonomy: Plans without cost estimates force approvers to accept unknown financial impact.
- Cost x Performance: Plans built on high-cost models force approvers to choose between performance and budget.
- Cost x Reliability: Surface the cost/reliability trade-off in the plan so approvers can make informed decisions.
- Cost x Security: Repeated plan submissions consume resources regardless of approval outcome — throttle submission frequency.
- Bounded Autonomous:
- Cost x Context: Unbounded context accumulation can exhaust token or cost budgets before the task completes.
- Cost x Autonomy: Without enforced budgets, retry loops or low-value exploration can cause massive cost overruns.
- Cost x Performance: Enforce model routing policies — agents optimizing for speed will default to the most expensive model without them.
- Cost x Reliability: Escalate to expensive models only when cheaper ones fail verification — exclusive use of top-tier models is financially unsustainable.
- Cost x Security: A triggered runaway loop causes significant financial damage before detection — enforce per-loop budget caps.
- Supervisory:
- Cost x Context: Passing un-summarized context between worker agents multiplies token costs at every coordination step.
- Cost x Autonomy: Inefficient worker orchestration or a single runaway worker can exhaust the shared budget for the entire agent team.
- Cost x Performance: Route sub-tasks by complexity, not by default — supervisors that always use top-tier workers waste budget.
- Cost x Reliability: Route tasks by risk level — routing all work to the most reliable (and expensive) worker is not cost-effective.
- Cost x Security: A single compromised worker entering a costly loop can exhaust the shared budget for the entire agent team.
Section 7 Citations (Sources & Links)
-
OpenAI API Docs: Prompt caching (reduced input token costs and latency through caching repeated prompt prefixes)
https://platform.openai.com/docs/guides/prompt-caching
(platform.openai.com) -
OpenAI Cookbook: Prompt Caching 101 (practical structuring guidance and examples)
https://developers.openai.com/cookbook/examples/prompt\_caching101/
(developers.openai.com) -
OpenAI API Docs: Production best practices (cost optimization as a production lever alongside latency and accuracy)
https://platform.openai.com/docs/guides/production-best-practices
(platform.openai.com) -
OpenAI Help Center: Controlling the length of OpenAI model responses (max tokens, prompting, stop sequences)
https://help.openai.com/en/articles/5072518-controlling-the-length-of-openai-model-responses
(help.openai.com) -
Anthropic Engineering: Introducing advanced tool use (tool search; quantified reduction in token overhead/context preservation)
https://www.anthropic.com/engineering/advanced-tool-use
(anthropic.com) -
Liu et al.: Budget-Aware Tool-Use Enables Effective Agent Scaling (agents need budget awareness; unified cost metric for tokens+tools; improved cost-performance frontier)
https://arxiv.org/abs/2511.17006
(arxiv.org) -
Liu et al.: Budget-Aware Tool-Use Enables Effective Agent Scaling (HTML; early stopping after self-verification under budget constraints)
https://arxiv.org/html/2511.17006v1
(arxiv.org)